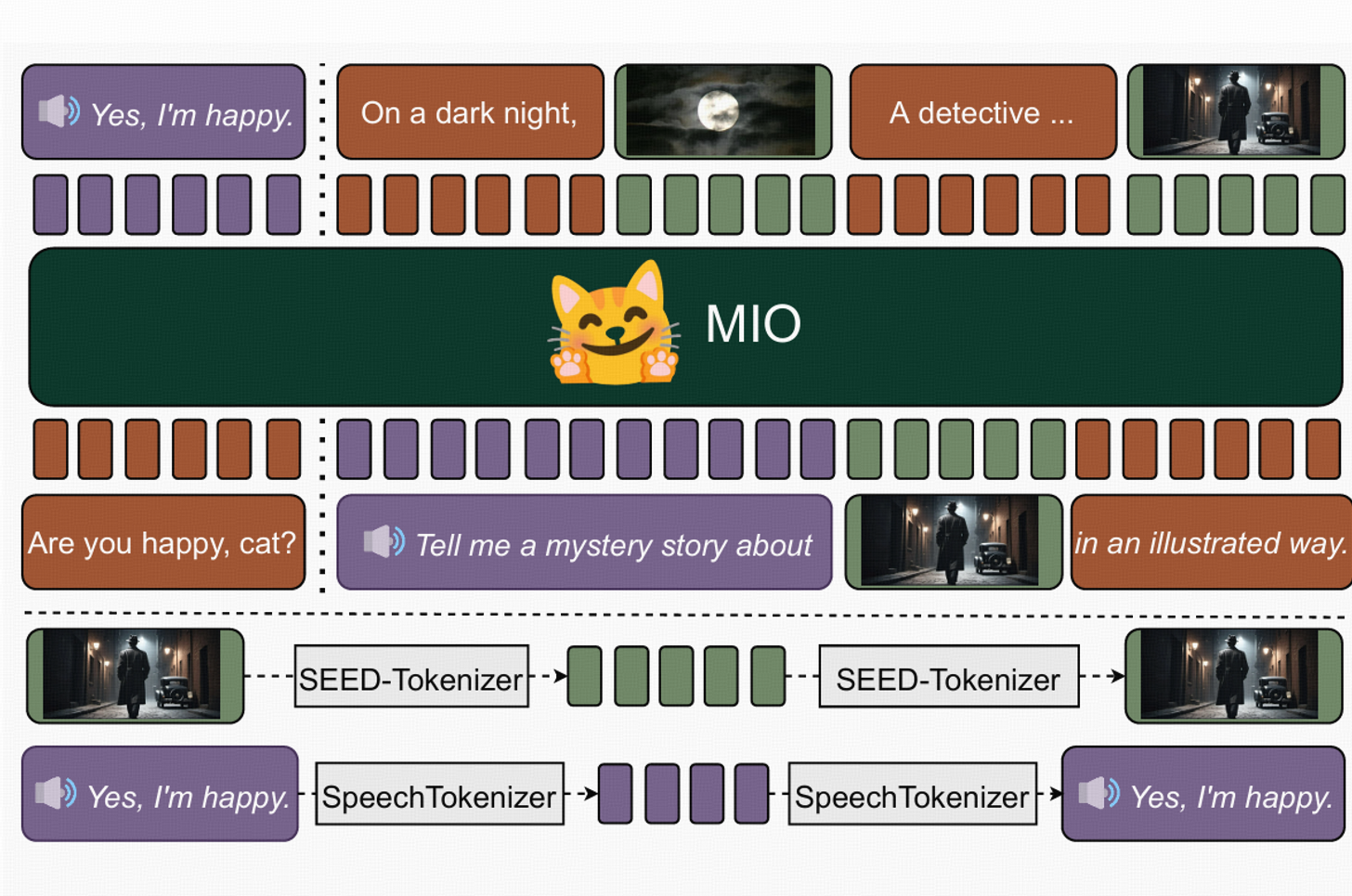
MIO: A Foundation Model on Multimodal Tokens
- Zekun Wang, King Zhu, Chunpu Xu, Wangchunshu Zhou, Jiaheng Liu, Yibo Zhang, Jiashuo Wang, Ning Shi, Siyu Li, Yizhi Li, Haoran Que, Zhaoxiang Zhang, Yuanxing Zhang, Ge Zhang, Ke Xu, Jie Fu, Wenhao Huang
- Under review
- A foundation model capable of understanding and generating speech, texts, images, and videos in an end-to-end and autoregressive manner. The model undergoes pre-training and SFT with 100+ GPUs.
[paper]
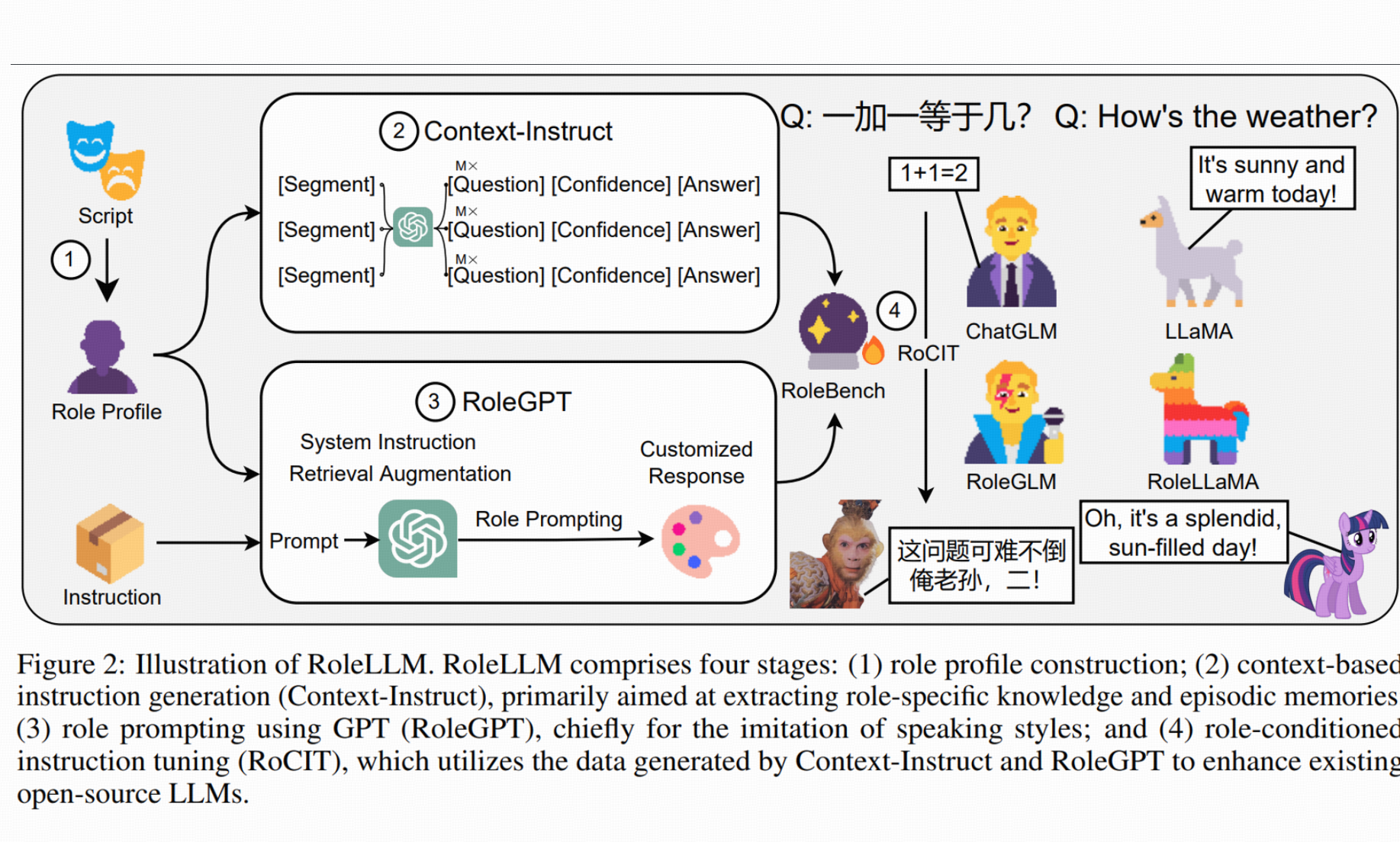
RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models
- Zekun Moore Wang*, Zhongyuan Peng*, Haoran Que*, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Jian Yang, Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Stephen W. Huang, Jie Fu, Junran Peng
- ACL 2024 Findings (posted by Aran Komatsuzaki)
- We introduce RoleLLM, a role-playing framework of data construction and evaluation (RoleBench), as well as solutions for both closed-source and open-source models (RoleGPT, RoleLLaMA, RoleGLM). We also propose Context-Instruct for long-text knowledge extraction and role-specific knowledge injection.
[paper] [github] [data] [opencompass] [Aran Komatsuzaki] [talk]

Interactive Natural Language Processing
- Zekun Wang*, Ge Zhang*, Kexin Yang, Ning Shi, Wangchunshu Zhou, Shaochun Hao, Guangzheng Xiong, Yizhi Li, Mong Yuan Sim, Xiuying Chen, Qingqing Zhu, Zhenzhu Yang, Adam Nik, Qi Liu, Chenghua Lin, Shi Wang, Ruibo Liu, Wenhu Chen, Ke Xu, Dayiheng Liu, Yike Guo, Jie Fu
- Springer Nature (editing) (posted by 机器之心)
- A survey on the next-generation LLM technology (100 pages), which covers the topics of Alignment, Tool-Use, KB, RAG, Agents, CoT, Embodied AI, Memory, SFT, etc.
[paper] [github] [机器之心] [talk]
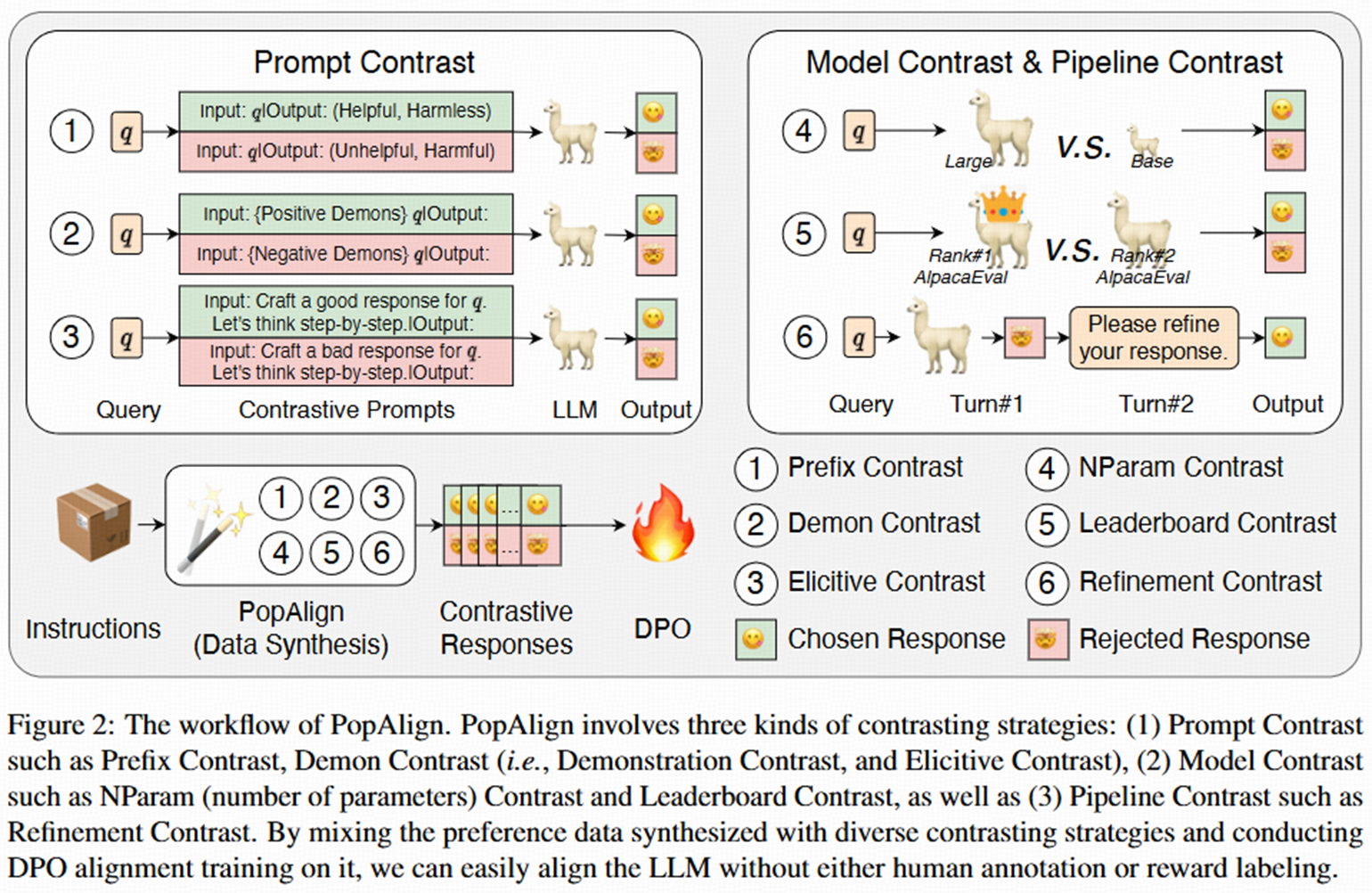
PopAlign: Prompt-Model-Pipeline Contrast for LLM Alignment through Comprehensive Contrastive Distillation
- Zekun Moore Wang, Wangchunshu Zhou, Shenzhi Wang, Kang Zhu, Jiaheng Liu, Ke Xu, Jie Fu, Wenhao Huang, Mrinmaya Sachan
- Under review (coming soon)
- We propose PopAlign, a novel framework for contrastive distillation by contrasting prompts, models, and pipelines. Our Elicitive Contrast approach can significantly improve the alignment performance.
[preview]
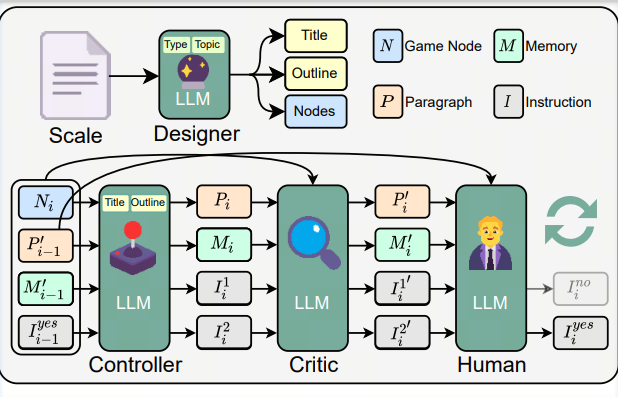
PsychoGAT: A Novel Psychological Measurement Paradigm through Interactive Fiction Games with LLM Agents
- Qisen Yang*, Zekun Wang*, Honghui Chen, Shenzhi Wang, Yifan Pu, Xin Gao, Wenhao Huang, Shiji Song, Gao Huang
- ACL 2024 Main (posted by 量子位)
- A LLM agent for psychological assessment. This agent can generate extra-long texts as an interactive game under the control of psychometric questionnaires and user interaction.
[paper] [twitter] [量子位]
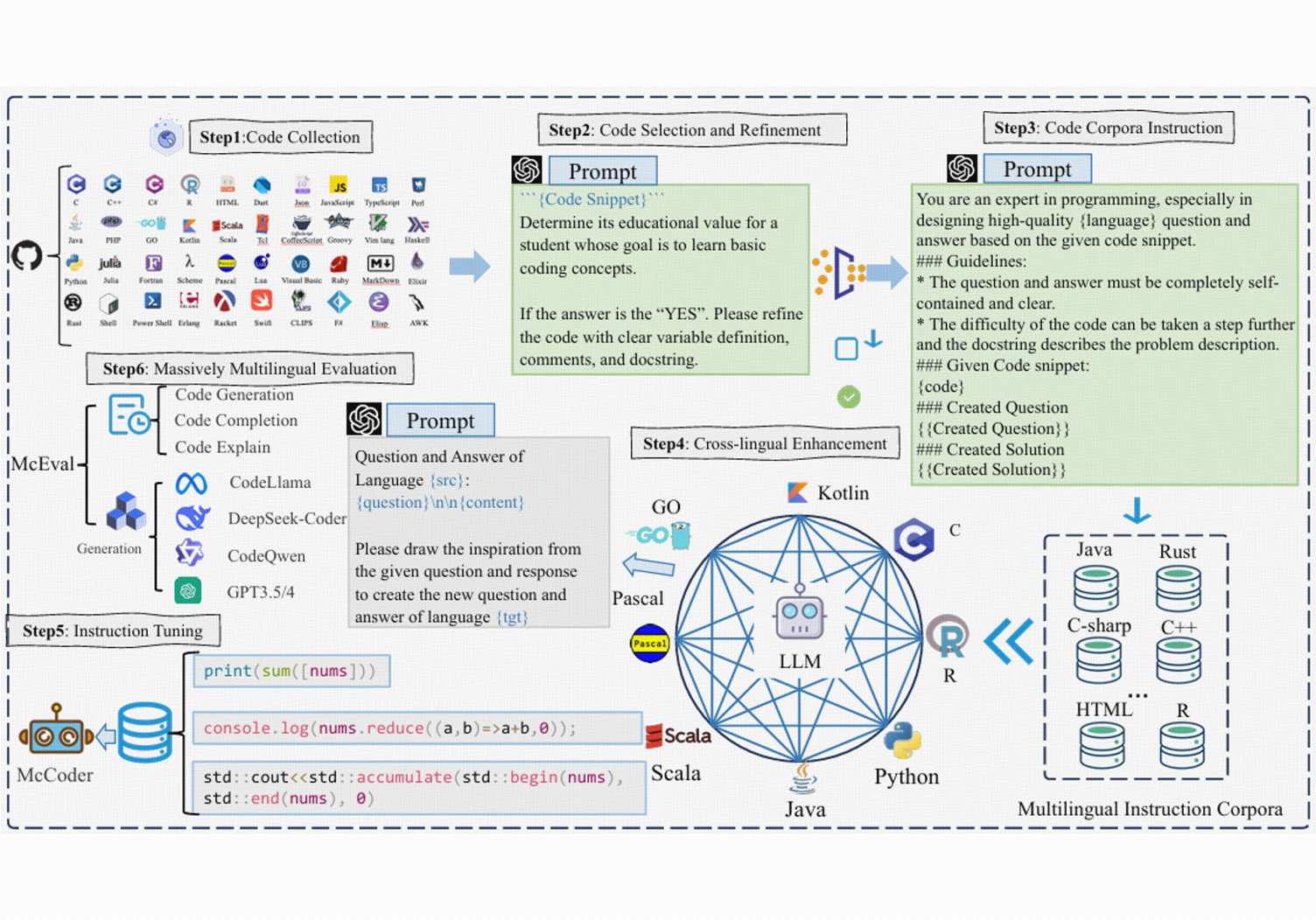
McEval: Massively Multilingual Code Evaluation
- Linzhen Chai*, Shukai Liu*, Jian Yang*, Yuwei Yin, Ke Jin, Jiaheng Liu, Tao Sun, Ge Zhang, Changyu Ren, Hongcheng Guo, Zekun Wang, Boyang Wang, Xianjie Wu, Bing Wang, Tongliang Li, Liqun Yang, Sufeng Duan, Zhoujun Li
- Under review, 2024
- To facilitate the development of code LLMs, we introduce a complete framework that includes the multilingual code instruction corpora, multilingual coder LLM (mCoder), and multilingual code evaluation benchmark.
[paper]
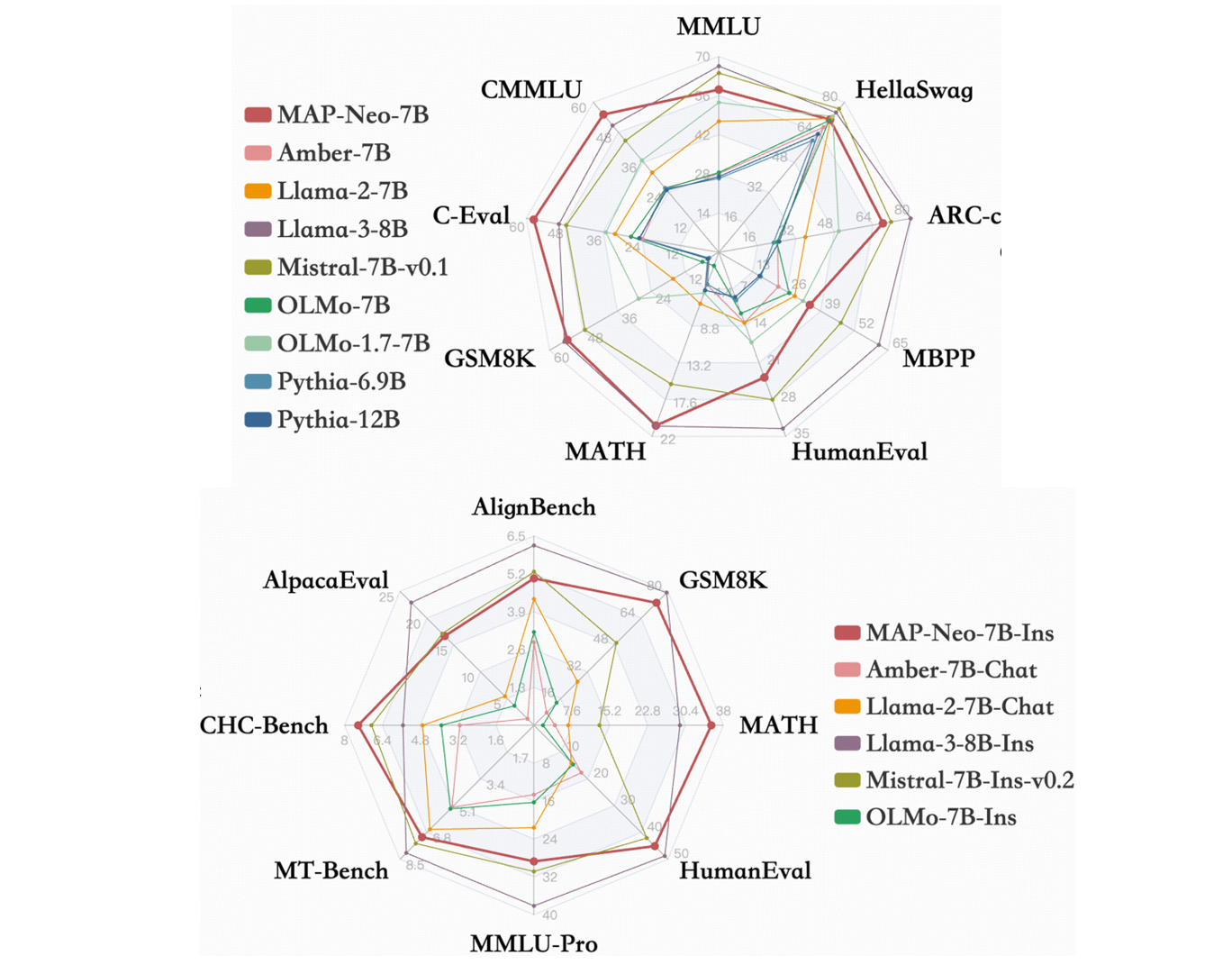
MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series
- Ge Zhang, Scott Qu, Jiaheng Liu, Chenchen Zhang, Chenghua Lin, Chou Leuang Yu, Danny Pan, Esther Cheng, Jie Liu, Qunshu Lin, Raven Yuan, Tuney Zheng, Wei Pang, Xinrun Du, Yiming Liang, Yinghao Ma, Yizhi Li, Ziyang Ma, Bill Lin, Emmanouil Benetos, Huan Yang, Junting Zhou, Kaijing Ma, Minghao Liu, Morry Niu, Noah Wang, Quehry Que, Ruibo Liu, Sine Liu, Shawn Guo, Soren Gao, Wangchunshu Zhou, Xinyue Zhang, Yizhi Zhou, Yubo Wang, Yuelin Bai, Yuhan Zhang, Yuxiang Zhang, Zenith Wang, Zhenzhu Yang, Zijian Zhao, Jiajun Zhang, Wanli Ouyang, Wenhao Huang, Wenhu Chen
- Technical Report, 2024
- A fully transparent and open-source generalist LLM with industry-level performance.
[paper] [daily papers]

LongIns: A Challenging Long-context Instruction-based Exam for LLMs
- Shawn Gavin, Tuney Zheng, Jiaheng Liu, Quehry Que, Noah Wang, Jian Yang, Chenchen Zhang, Wenhao Huang, Wenhu Chen, Ge Zhang
- Under review, 2024
- A benchmark for evaluating long-context LLMs through instruction-based exams.
[paper] [daily papers]
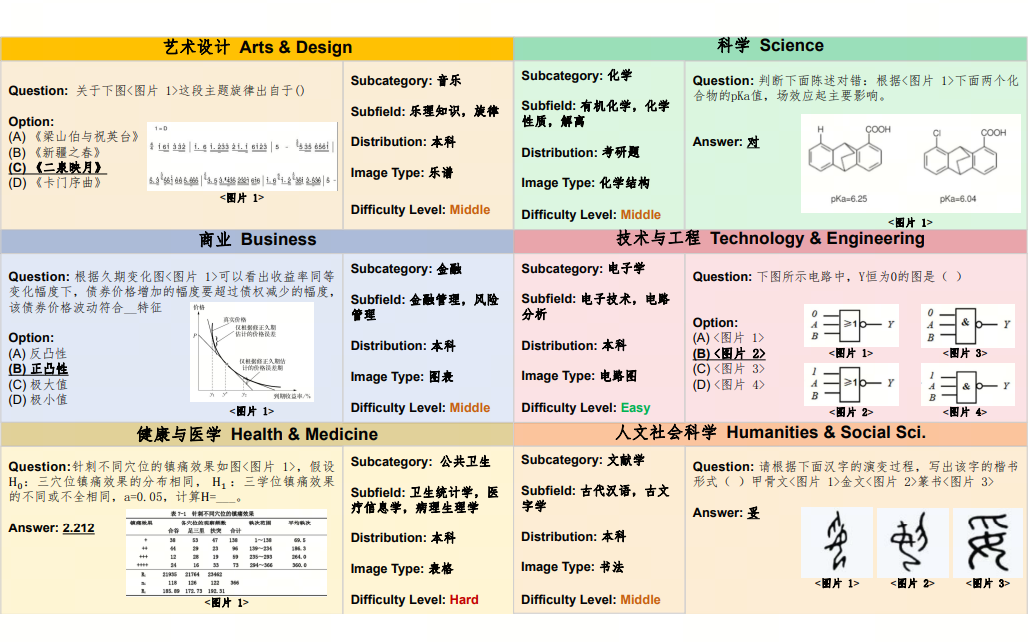
CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark
- Ge Zhang*, Xinrun Du*, Bei Chen*, Yiming Liang, Tongxu Luo, Tianyu Zheng, Kang Zhu, Yuyang Cheng, Chunpu Xu, Shuyue Guo, Haoran Zhang, Xingwei Qu, Junjie Wang, Ruibin Yuan, Yizhi Li, Zekun Wang, Yudong Liu, Yu-Hsuan Tsai, Fengji Zhang, Chenghua Lin, Wenhao Huang, Wenhu Chen, Jie Fu
- Under review, 2024 (posted by 机器之心)
- A Chinese massive multi-discipline multimodal understanding benchmark.
[paper] [机器之心] [dataset] [github] [AK]
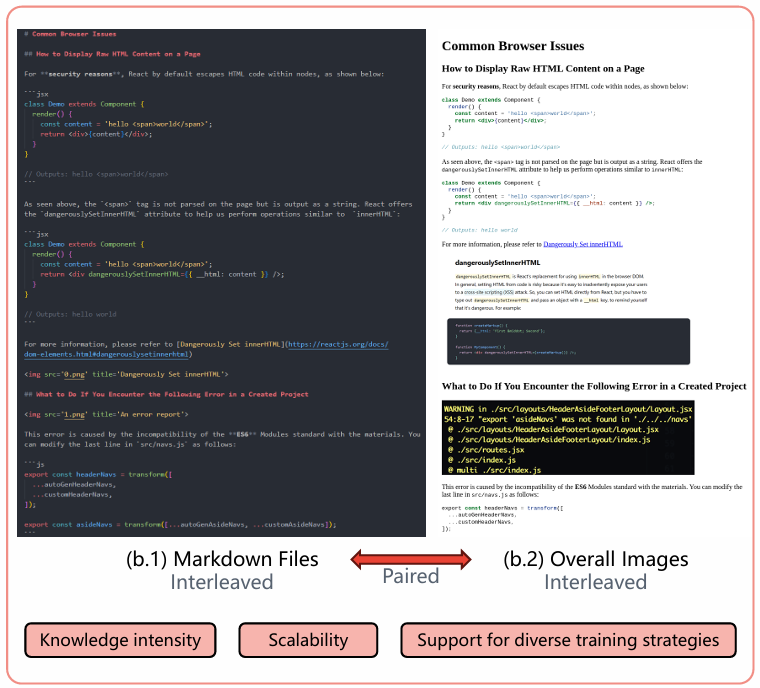
PIN: A Knowledge-Intensive Dataset for Paired and Interleaved Multimodal Documents
- Junjie Wang, Yin Zhang, Yatai Ji, Yuxiang Zhang, Chunyang Jiang, Yubo Wang, Kang Zhu, Zekun Wang, Tiezhen Wang, Wenhao Huang, Jie Fu, Bei Chen, Qunshu Lin, Minghao Liu, Ge Zhang, Wenhu Chen
- Under review, 2024
- We introduce a new multimodal dataset, PIN-14M, for Paired and Interleaved multimodal documents. It supports training of knowledge-intensive MLLMs with enhanced OCR abilities.
[paper]
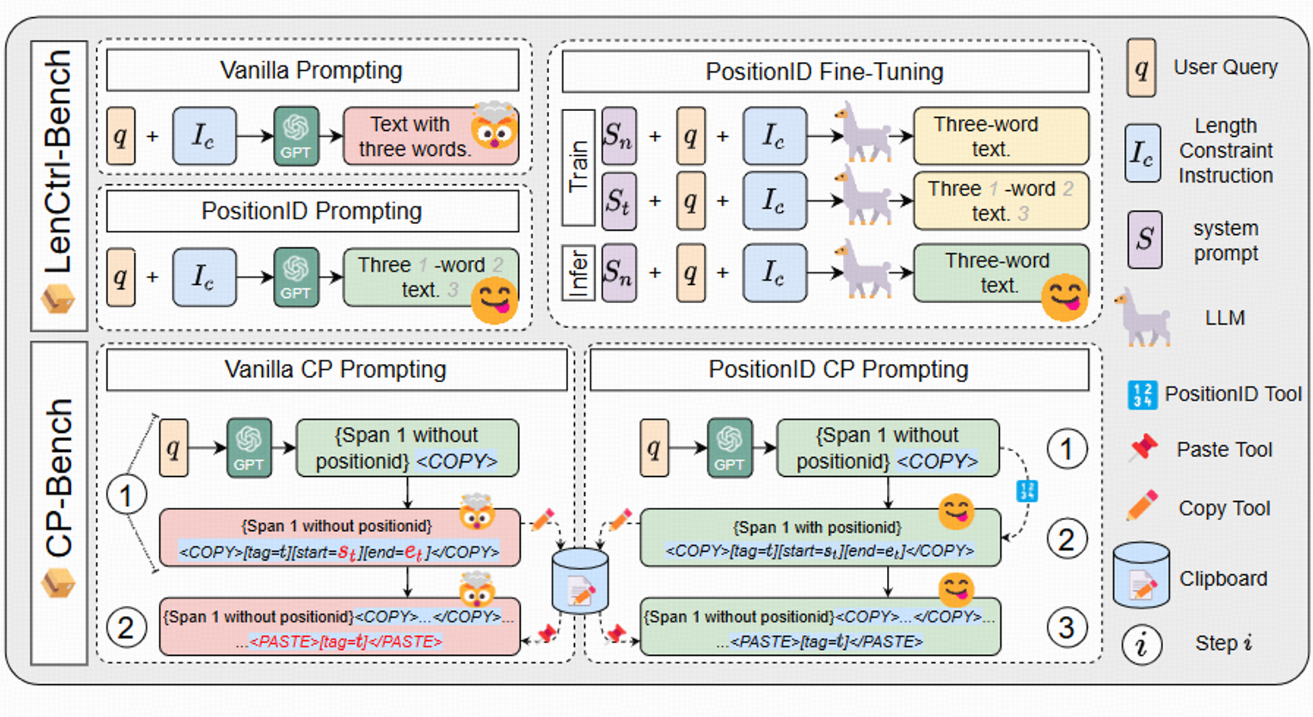
PositionID: LLMs can Control Lengths, Copy and Paste with Explicit Positional Awareness
- Zekun Wang, Feiyu Duan, Yibo Zhang, Wangchunshu Zhou, Ke Xu, Wenhao Huang, Jie Fu
- EMNLP 2024 Findings (coming soon)
- We propose methods for enhancing the LLMs' abilities in length control and copy-paste tool-use.
[preview]
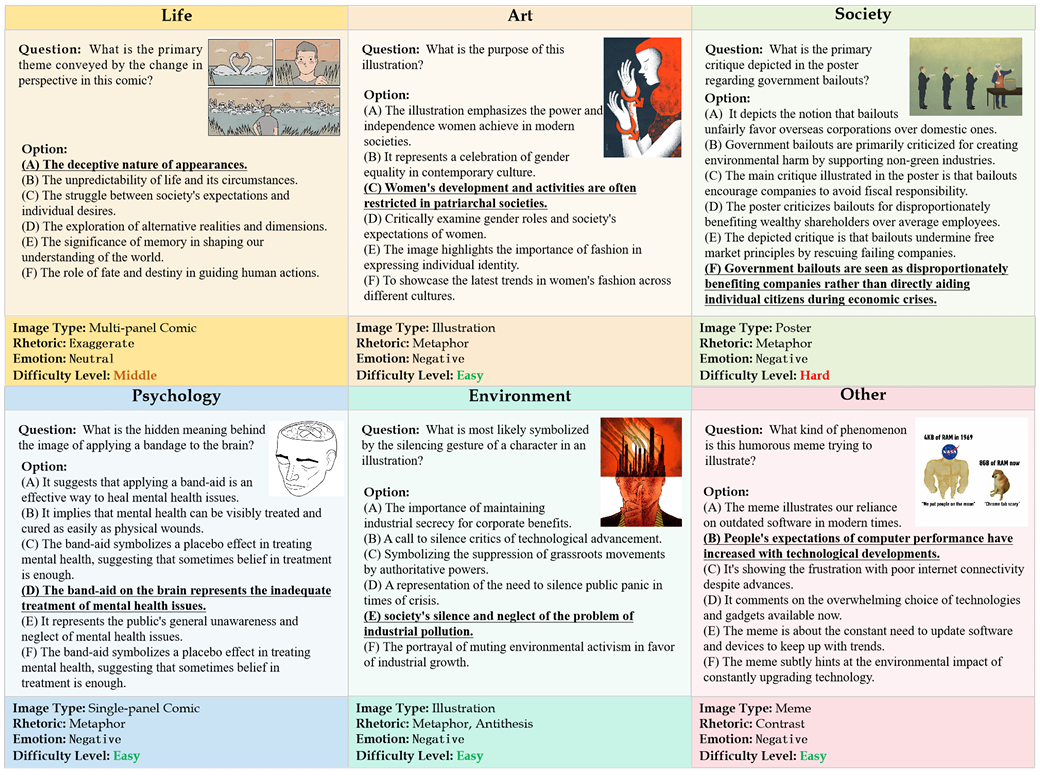
II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
- Ziqiang Liu, Feiteng Fang, Xi Feng, Xinrun Du, Chenhao Zhang, Zekun Wang, Yuelin Bai, Qixuan Zhao, Liyang Fan, Chengguang Gan, Hongquan Lin, Jiaming Li, Yuansheng Ni, Haihong Wu, Yaswanth Narsupalli, Zhigang Zheng, Chengming Li, Xiping Hu, Ruifeng Xu, Xiaojun Chen, Min Yang, Jiaheng Liu, Ruibo Liu, Wenhao Huang, Ge Zhang, Shiwen Ni
- NeurIPS 2024 (D&B Track)
- We propose the Image Implication Understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images.
[paper]
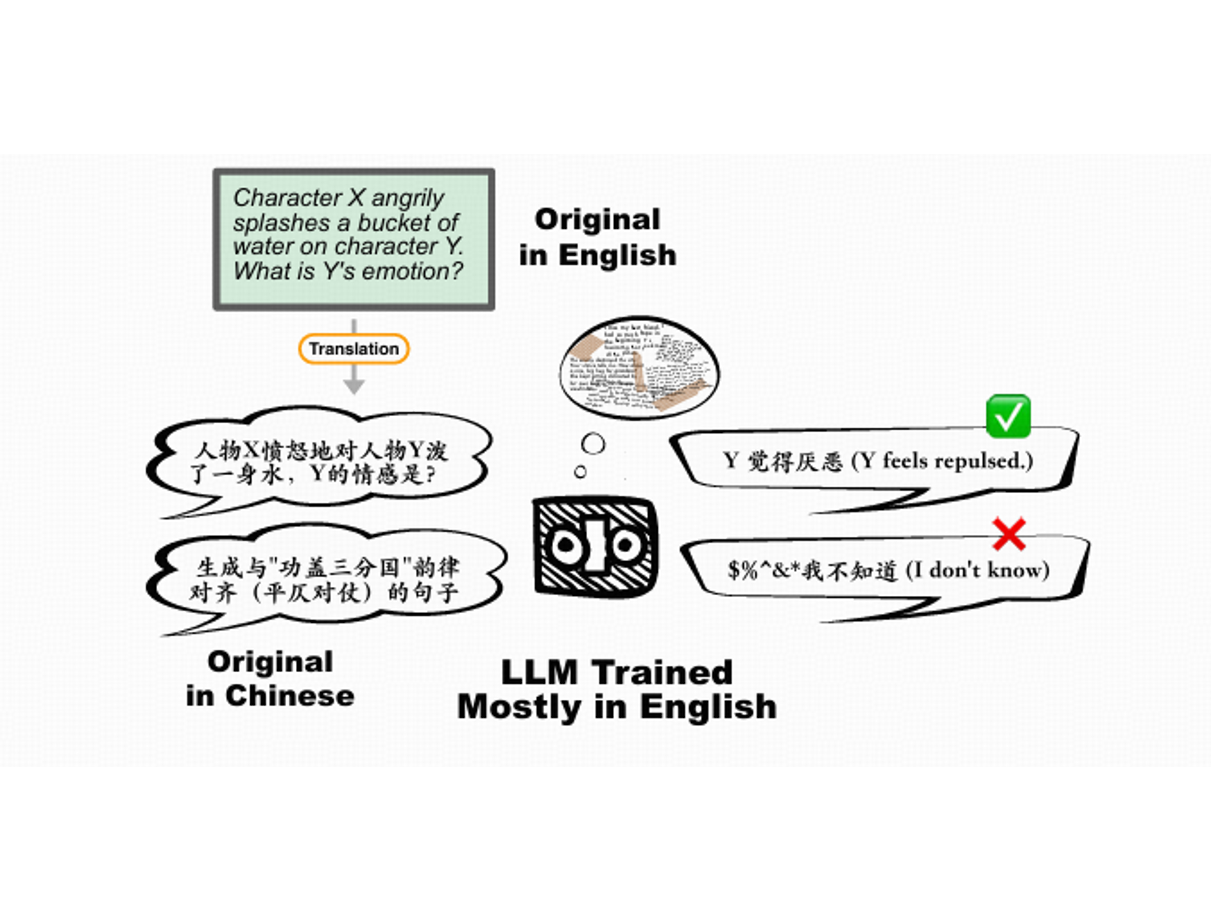
CIF-Bench: A Chinese Instruction-Following Benchmark for Evaluating the Generalizability of Large Language Models
- Yizhi Li, Ge Zhang, Xingwei Qu, Jiali Li, Zhaoqun Li, Zekun Wang, Hao Li, Ruibin Yuan, Yinghao Ma, Kai Zhang, Wangchunshu Zhou, Yiming Liang, Lei Zhang, Lei Ma, Jiajun Zhang, Zuowen Li, Stephen W. Huang, Chenghua Lin, Wenhu Chen, Jie Fu
- ACL 2024 Findings
- Designed to evaluate the zero-shot generalizability of LLMs to the Chinese language.
[paper]
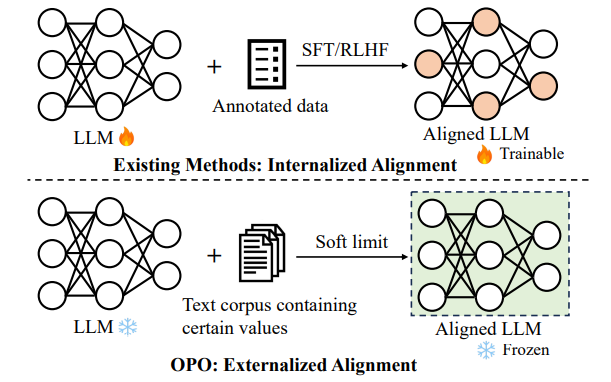
Align on the Fly: Adapting Chatbot Behavior to Established Norms
- Chunpu Xu, Steffi Chern, Ethan Chern, Ge Zhang, Zekun Wang, Ruibo Liu, Jing Li, Jie Fu, Pengfei Liu
- Under review, 2024 (posted by 机器之心)
- A novel method that dynamically aligns LLMs with human values.
[paper] [机器之心]
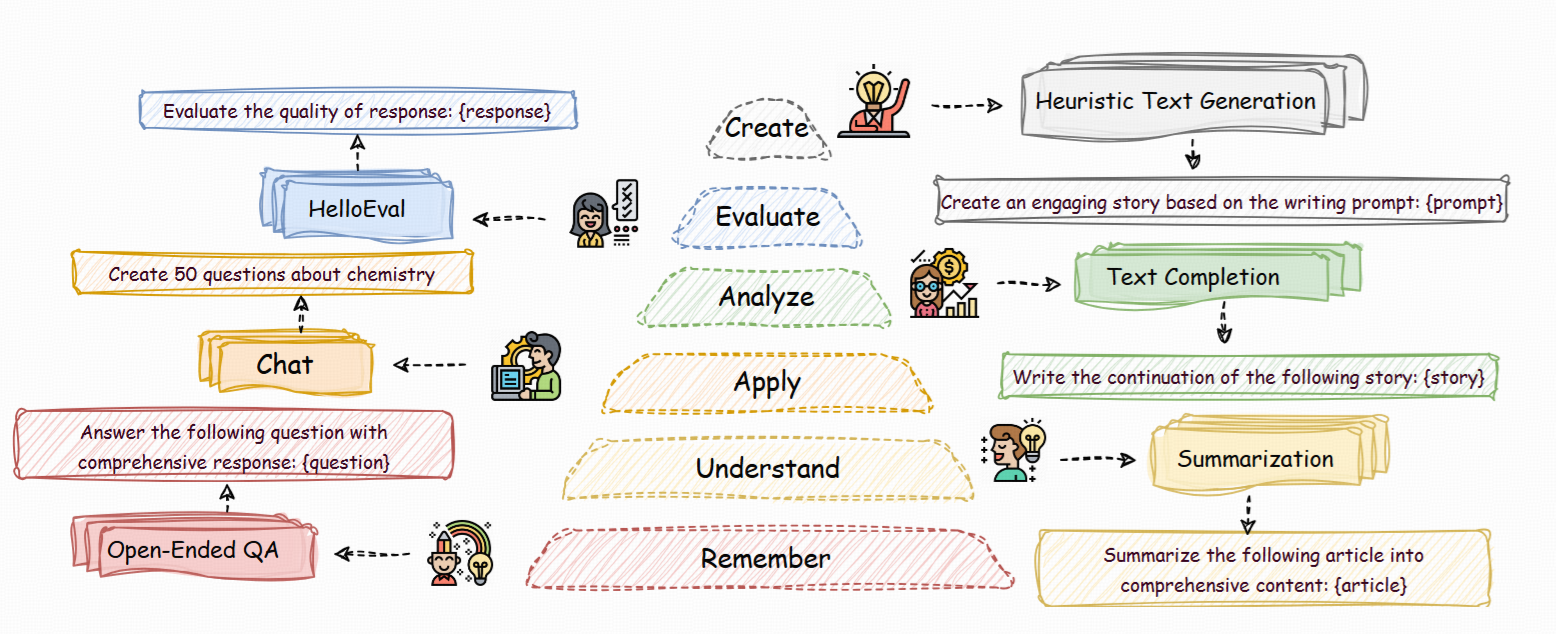
HelloBench: Evaluating Long Text Generation Capabilities of Large Language Models
- Haoran Que, Feiyu Duan, Liqun He, Yutao Mou, Wangchunshu Zhou, Jiaheng Liu, Wenge Rong, Zekun Moore Wang, Jian Yang, Ge Zhang, Junran Peng, Zhaoxiang Zhang, Songyang Zhang, Kai Chen
- Under review, 2024
- A novel hierarchical benchmark for long text generation based on Bloom's Taxonomy.
[paper] [daily papers]